
Description
When I first started out solving real world problems within data science, I found it difficult to find a specific way to approach a problem so that I could effectively solve it. I had an idea as to how I would approach problems as I am a natural problem solver, however, sometimes I can be a stickler for a process or a method to provide some sort of guidance. I don't believe there is only ever ONE way to do anything, as this mentality limits creativity and innovation and the world would be a boring place. Through experience in competitions and my job, I have picked up on a great way to approach any problem.
As mentioned, there is no ONE way to solve a problem, there never has been, this IS science. Science is about developing hypotheses, testing new things out, learning and developing through what we've learnt. That's what I continually do throughout the process of solving any data science problem. I've seen similar problems in every project i've engaged in and found the approach I describe here to be a useful first approach to a problem. This post assumes that you have your data ready for analysis and no need for extracting from sources, usually relational databases. I firmly believe that every problem is unique and there is no standard way to solve every data science problem in the world however, this is my standardised framework to handling data science problems.
As mentioned, there is no ONE way to solve a problem, there never has been, this IS science. Science is about developing hypotheses, testing new things out, learning and developing through what we've learnt. That's what I continually do throughout the process of solving any data science problem. I've seen similar problems in every project i've engaged in and found the approach I describe here to be a useful first approach to a problem. This post assumes that you have your data ready for analysis and no need for extracting from sources, usually relational databases. I firmly believe that every problem is unique and there is no standard way to solve every data science problem in the world however, this is my standardised framework to handling data science problems.
The Detail
1. Understand the Problem
First things first, and this may seem really obvious, but it is often skimmed over very briefly or even overlooked to some extent, understand your problem. I believe a comprehensive understanding of the problem plays a huge role throughout the project. Before you even begin to embark on your project journey, you need to understand how you're going to go about things as well as what the end goal is.
There are numerous problems that can be classed as data science problems. These revolve around optimisation , predictive analytics and decision making. However, there are really three very popular types of problems that the majority of problem solving falls under which are;
1. Classification Problems (Supervised Learning)
2. Regression Problems (Supervised Learning)
3. Pattern Recognition / Clustering (Unsupervised Learning)
Data science problems are not constrained to these three types of problems as you have reinforcement learning, forecasting and much more, however, these are the most popular.
Within each of these fields there are a number of techniques and methods that can be applied and a thorough understanding of the problem will enable you to understand which techniques to use and why.
There are numerous problems that can be classed as data science problems. These revolve around optimisation , predictive analytics and decision making. However, there are really three very popular types of problems that the majority of problem solving falls under which are;
1. Classification Problems (Supervised Learning)
2. Regression Problems (Supervised Learning)
3. Pattern Recognition / Clustering (Unsupervised Learning)
Data science problems are not constrained to these three types of problems as you have reinforcement learning, forecasting and much more, however, these are the most popular.
Within each of these fields there are a number of techniques and methods that can be applied and a thorough understanding of the problem will enable you to understand which techniques to use and why.
2. Understand Your Data
Next step is also very important, and thats to fully understand your data. Understanding your data consists of an in depth review of the data to fully understand it as this will enable you to manipulate and navigate that data in a more effective way and help you understand the uniqueness and traits of the data. Get to know your data as this will pay off later on when tweaking data and fitting models to the data.
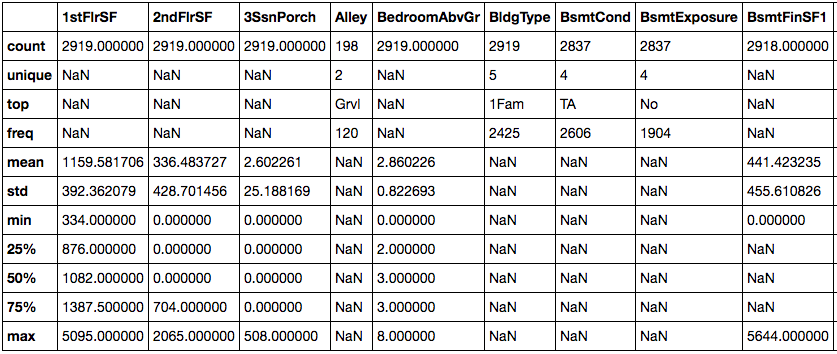
Tho understand the data, there are a number of things that you can do. The first thing is to understand the features of your data and all their nuances. This is a very important stage. When I say "features" of the data, I am referring to the columns that define the rows of the data. Understanding the features and how they have been captured will give you better insight as to what are anomalies, what to expect and how to go about treating the feature in cleaning the data. A good place to start with this is to start off with a simple describe() function which is available in a number of packages. As a pythonista, i tend to use the pandas library which have handy .describe() and .info() method attached to the DataFrame. I use the code below, yielding the following results:
Tho understand the data, there are a number of things that you can do. The first thing is to understand the features of your data and all their nuances. This is a very important stage. When I say "features" of the data, I am referring to the columns that define the rows of the data. Understanding the features and how they have been captured will give you better insight as to what are anomalies, what to expect and how to go about treating the feature in cleaning the data. A good place to start with this is to start off with a simple describe() function which is available in a number of packages. As a pythonista, i tend to use the pandas library which have handy .describe() and .info() method attached to the DataFrame. I use the code below, yielding the following results:
|
|
This is a good start to help develop an understanding. I supplement this with plots so I can visualise the data. I find that visualisations provide a bit more insight as to how the data is shaped. These plots include mostly histograms, boxplots or whatever plot necessary to understand the data.
Understanding the data also includes understanding how the features are related and how they interact with each other. This is where visualisations become very useful! I use similar plots to before except I mix in other variables.
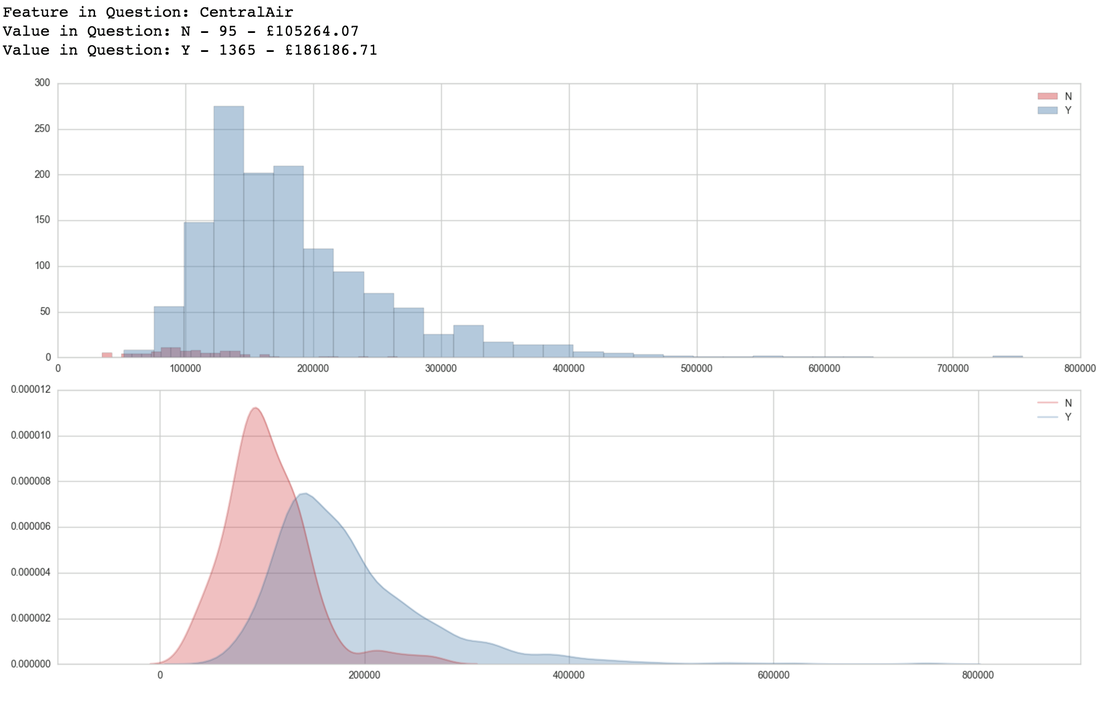
For example, if i was looking at a categorical feature, I would split the data by those categories and look at the distributions with regards to another variable, usually the target variable. I tend to do this in bulk with the use of loops like below, yielding results like shown below;
Understanding the data also includes understanding how the features are related and how they interact with each other. This is where visualisations become very useful! I use similar plots to before except I mix in other variables.
For example, if i was looking at a categorical feature, I would split the data by those categories and look at the distributions with regards to another variable, usually the target variable. I tend to do this in bulk with the use of loops like below, yielding results like shown below;
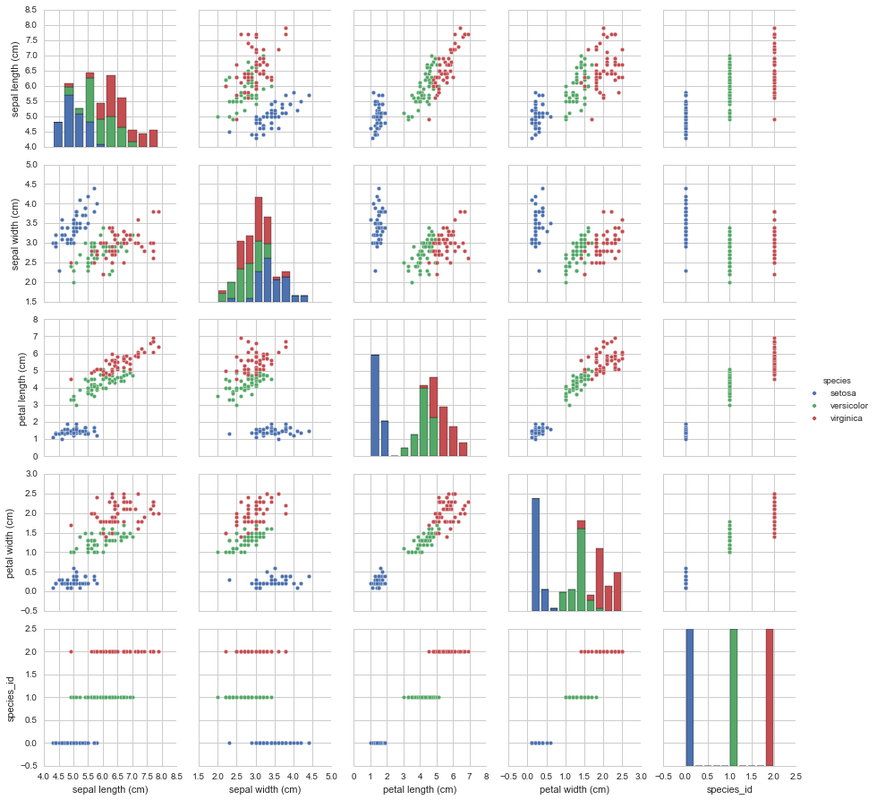
The seaborn package has a pretty cool pairplot which is a great way to visualise the relationships in your data. The pairplot plots pairs of features together in a scatter graph in order to show the relationship between the paired features. Where two features are the same, it plots the histogram for that given feature. This is a great way to quickly visualise relationships in your data. This may be better to do when you have small datasets or if you subset your dataset to view relationships, otherwise, datasets with more than 15 features tends to be quite difficult to read.
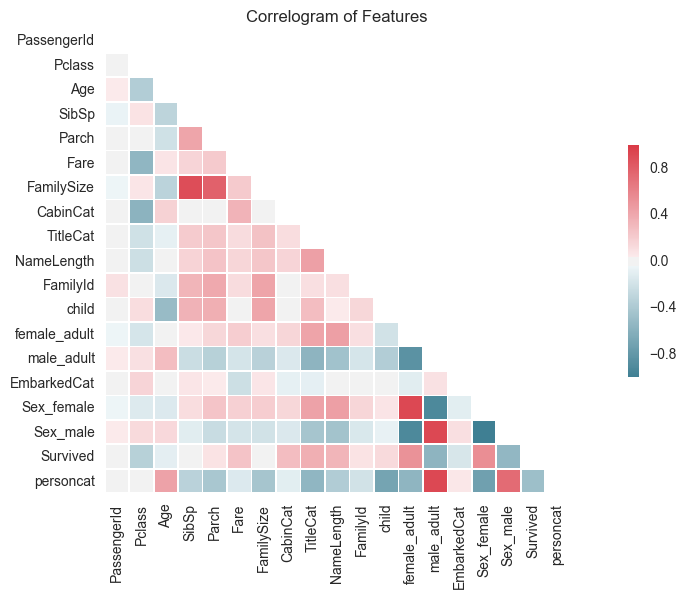
One last cool visualisation to help understand your data is a correlogram. This colour codes correlation scores into a grid so you are able to quickly spot highly correlated features, positively (red) or negatively (blue).
3. Clean, Feature Engineer, Process The Data
This is notoriously where the majority of any data project lies... in the cleaning of the data so that it is suitable for processing.
This is where you use your understanding of the problem and the data, so you are able to best process the data. For example, If you know that your solution requires continuous variables only, then you can apply a number of methods to achieve this, either by dropping variables or transformations.
Knowledge of the problem and appropriate solution, will give you a direction in which you can work.
To find out how to do clean and process data, keep an eye our for my "data wrangling techniques" series which goes into tips and tricks you can use to manage your data so that you're able to make the most of your data.
With a thorough understanding of the data and how the features interact, this will put you in a great position to begin feature engineering! This is where you can explore through your data in order to uncover features that could potentially increase predictive power.
However, you must be cautious about information leak throughout this process. This stage would also be a great time to look at variable reduction techniques should you have hundreds of variables whilst considering the models that you're intending to use.
This is where you use your understanding of the problem and the data, so you are able to best process the data. For example, If you know that your solution requires continuous variables only, then you can apply a number of methods to achieve this, either by dropping variables or transformations.
Knowledge of the problem and appropriate solution, will give you a direction in which you can work.
To find out how to do clean and process data, keep an eye our for my "data wrangling techniques" series which goes into tips and tricks you can use to manage your data so that you're able to make the most of your data.
With a thorough understanding of the data and how the features interact, this will put you in a great position to begin feature engineering! This is where you can explore through your data in order to uncover features that could potentially increase predictive power.
However, you must be cautious about information leak throughout this process. This stage would also be a great time to look at variable reduction techniques should you have hundreds of variables whilst considering the models that you're intending to use.
4. Understand & Test Your Models
Once you’re happy with your cleaned data, what I like to do is test a bunch of models in a default setting and try to maintain some consistency across models (learning rates, random states train volume, test volume).
Nowadays, there are a number of data science libraries that enable you to plug and play, so you don’t lose too much time in building the models. I HIGHLY recommend fully understanding the models that you are using and how they work in order to understand how to pick optimal parameters to best solve your problem. For example, random forest models and their "Out Of Bag" characteristic, you know that there is no need to cross validate because of this. So to counter this, you could perhaps make 100% of the data made available for training.
These methods give me some sort of idea as to which models perform best on your data. Through your understanding of the data, you are able to get some idea as to which models will perform better (i.e. a lot of linearly related variables (high correlations) will tend to perform better in linear models generally).
I also like to take the time to run each model a number of times within a loop in order to obtain a mean performance of the model. My preference is to also train the model on ALL the data and test the data on the same complete training set, knowing full well that overfitting will occur within these methods. I then run a 5 or 10 fold cross validated run of the models and take the mean of the 5 or 10 models to assess performance of each model.
This is also a great time to experiment with custom ensemble methods. I wont go into too much detail into how I go about ensembling, however, I can write up another blog should it be requested, but in general, some features perform better than others in different models and the trick is to fully understand how the models work to find the perfect mix of features with the right models to provide a better prediction (Divide (Maybe Bag) and Conquer). This concept can be applied not only on features but the rows of data too!
Nowadays, there are a number of data science libraries that enable you to plug and play, so you don’t lose too much time in building the models. I HIGHLY recommend fully understanding the models that you are using and how they work in order to understand how to pick optimal parameters to best solve your problem. For example, random forest models and their "Out Of Bag" characteristic, you know that there is no need to cross validate because of this. So to counter this, you could perhaps make 100% of the data made available for training.
These methods give me some sort of idea as to which models perform best on your data. Through your understanding of the data, you are able to get some idea as to which models will perform better (i.e. a lot of linearly related variables (high correlations) will tend to perform better in linear models generally).
I also like to take the time to run each model a number of times within a loop in order to obtain a mean performance of the model. My preference is to also train the model on ALL the data and test the data on the same complete training set, knowing full well that overfitting will occur within these methods. I then run a 5 or 10 fold cross validated run of the models and take the mean of the 5 or 10 models to assess performance of each model.
This is also a great time to experiment with custom ensemble methods. I wont go into too much detail into how I go about ensembling, however, I can write up another blog should it be requested, but in general, some features perform better than others in different models and the trick is to fully understand how the models work to find the perfect mix of features with the right models to provide a better prediction (Divide (Maybe Bag) and Conquer). This concept can be applied not only on features but the rows of data too!
5. Optimise Your Data
This can be quite time consuming and an arduous task but to get those incremental increases in performance, it’s necessary!
At this point, I tweak the data and try different treatments of variables. As you’re cleaning the data, you will come across variables which you can treat in different ways. Obviously, this forces you to choose one and perhaps the other treatment is better for modelling purposes. This is where you can try out changes and assess the changes in results. You take what you learn at every iteration to see how you can better process that data.
At this point, I tweak the data and try different treatments of variables. As you’re cleaning the data, you will come across variables which you can treat in different ways. Obviously, this forces you to choose one and perhaps the other treatment is better for modelling purposes. This is where you can try out changes and assess the changes in results. You take what you learn at every iteration to see how you can better process that data.
6. Optimise Your Models
This can also be quite time consuming however this can be done relatively quickly given you have the right amount of computing power!
What I tend to do at this point is attempt to tweak the model parameters to try get an optimal performing model.
Here I build pipelines in which I include a Grid Search, preferably randomised. What a grid search does is essentially test a bunch of parameters that you set. It tests all the combination of parameters you set and returns a model with the optimal parameters. This is quite computationally intensive, especially when you are doing it to 4 different models with about 4-7 custom parameters with 10 variations each as well as cross validation! I’ve left this running over night at times, however, there are web services that enable you to access more compute to reduce the time required to run such an operation.
A Grid Search looks something like:
What I tend to do at this point is attempt to tweak the model parameters to try get an optimal performing model.
Here I build pipelines in which I include a Grid Search, preferably randomised. What a grid search does is essentially test a bunch of parameters that you set. It tests all the combination of parameters you set and returns a model with the optimal parameters. This is quite computationally intensive, especially when you are doing it to 4 different models with about 4-7 custom parameters with 10 variations each as well as cross validation! I’ve left this running over night at times, however, there are web services that enable you to access more compute to reduce the time required to run such an operation.
A Grid Search looks something like:
My main approach is that I would have a dictionary where the keys would be the names of the models you are looping over, and the value would be a another dictionary (nested dictionaries) with two keys, 'model' and 'param_grid' where the actual model and another dictionary as shown above with the param_grid. This seems complex but makes a lot of sense when you can see it. So it looks like this 👇
I would write a loop that would loop over the model selections and parameters and fit a grid search after which I would take the best parameters away. Luckily, there is a cross validation parameter within the grid search. There are many types of grid searches available within the scikit-learn package. You can find more details HERE.
You also have to make sure the parameters that you are using for the grid-search are appropriate. For example, if you’re working with something like Random Forest and you’re looking to decide on an appropriate number of trees, you’re better off running a loop over a number of trees and plotting the results of the error of the models and selecting the number of trees where the curve plateaus instead of grid search.
You also have to make sure the parameters that you are using for the grid-search are appropriate. For example, if you’re working with something like Random Forest and you’re looking to decide on an appropriate number of trees, you’re better off running a loop over a number of trees and plotting the results of the error of the models and selecting the number of trees where the curve plateaus instead of grid search.
7. Build, Predict & Submit/Productionize
Now that you know how to clean your data, what model you would like to use and the optimal parameters of that model, you can train your model and begin to predict on your problem test set.
If this model is being put into production, you will need to look into ways of monitoring the performance of the model over time in case you need to rebuild and train your model due to declining performance.
There are a number of things that you can do at this point. If this model is going into production, a popular approach is to build a pipeline. Pipelines are a great way to standardise an approach in manipulating data and are very popular in the data science world. Saves you the time taken to process and predict new incoming data. You can build a pipeline that takes in new data, cleans, transforms and does whatever it needs to do to the data, then uses the model that you previously made and produces an output. To make effective pipelines, a thorough understanding of your data and how to clean it ensuring that no surprises pop up and break your pipeline is essential. If you would like to hear more about pipelines, feel free to drop a comment and i can answer questions there or look to write a new post solely on pipelines and the numerous platforms that allow you to build them!
If this model is being put into production, you will need to look into ways of monitoring the performance of the model over time in case you need to rebuild and train your model due to declining performance.
There are a number of things that you can do at this point. If this model is going into production, a popular approach is to build a pipeline. Pipelines are a great way to standardise an approach in manipulating data and are very popular in the data science world. Saves you the time taken to process and predict new incoming data. You can build a pipeline that takes in new data, cleans, transforms and does whatever it needs to do to the data, then uses the model that you previously made and produces an output. To make effective pipelines, a thorough understanding of your data and how to clean it ensuring that no surprises pop up and break your pipeline is essential. If you would like to hear more about pipelines, feel free to drop a comment and i can answer questions there or look to write a new post solely on pipelines and the numerous platforms that allow you to build them!
Conclusion
In my experience, this is the bare bones of how I go about solving data science problems. There are a number of other issues outside of this that occur in the real world like the collection of the data and productionizing of models however this is out of the scope of this. In most cases, between understanding the problem and understanding the data is the formation of the data to solve the problem. This would require the use of extracting data, often from relational databases, and building the data from there. A lot of the compute and cleaning of the data can be done at this point if you understand your data and problem to some degree.
The main steps highlighted in this post is;
Remember, every project is different and how you go about solving them can vary! I've found that if i stick to these core concepts behind solving data science problems, i'll be just fine. The techniques behind how you go about these steps may vary, though the framework remains constant.
I hope this helps anyone that is struggling with a method to solving data science problems or at least an interesting read.
If there is any area in this list that you would like me to go into more detail then please feel free to leave a comment below and I will either answer within a reply or even write a new post!
Thanks For Reading!
The main steps highlighted in this post is;
- Understand The Problem
- Understand Your Data
- Clean, Feature Engineer & Process The Data
- Understand and Test Your Models
- Optimise Your Data
- Optimise Your Models
- Build, Predict & Submit / Productionize
Remember, every project is different and how you go about solving them can vary! I've found that if i stick to these core concepts behind solving data science problems, i'll be just fine. The techniques behind how you go about these steps may vary, though the framework remains constant.
I hope this helps anyone that is struggling with a method to solving data science problems or at least an interesting read.
If there is any area in this list that you would like me to go into more detail then please feel free to leave a comment below and I will either answer within a reply or even write a new post!
Thanks For Reading!
