
Intro
I have developed an API that enables people to stack models to build and ensemble that add meta-features to your main data to then use with a final stacking model. This means that when building a machine learning solution, you are able to have multiple machine learning algorithms contribute to a final model in an attempt to get the best out of each model. This implementation allows you to dictate which columns each model should look at as you can optimise individual models and see that different combinations of features will work better/worse with different models. This implementation also give you the ability to blend. Blending is a technique that is used to overcome overfitting by K-Fold production of the meta-features and aggregating each models result during the prediction phase.
Description - What is Stacking?
Stacking is a well-known method in Data Science where you attempt to get the best of a number of models into one final model. Based on this description, it's clear that this is an ensemble method. Ensemble methods use multiple methods to achieve better predictions thorough the use of many models working together.
When stacking, you can have a number of models that you wish to stack together and a model to join them all together. The initial individual models use the core data to generate their own predictions. These predictions tend to work best in stacking when generating either probabilistic outputs (usually the "predict_proba" method in scikit-learn models) as opposed to the threshold assigned binary predictions (the standard "predict" method in scikit-learn models). There are some models that do not provide the most-desired output of a probability, in which case the binary classifications are used, however, where possible, the probabilities are used as the meta-features. These predictions are then used in the final model as features known as meta-features. The final model will take all the original training data as well as the meta-features (predictions) generated by the other models and then generate predictions based on those.
Reasoning - Why Stacking?
Stacking has proven to improve predictions in comparison to other models. They are more complex to implement and depending on your environment or objectives, may be overkill to implement into production. Here is where you begin to consider the tradeoff between complexity and performance. In most cases, stacking only marginally improves performance by about 1 to 10%(max i've seen). To consider your real-world application, even less than 1% could save millions for a company. In most cases, these incremental changes are better earned through better handling of the training data and generating more meaningful features, but once you have done all of that, stacking could take your results to the next level.
Stacking is a very popular technique used within kaggle competitions, as this gives you the chance to improve your score where even so much as a 1% increase can result in placing in the top rankings in a competition. In most stacking solutions, they are tailored specifically for the problem, and this implementation allows you to customise and tailor features for each model.
Stacking is a very popular technique used within kaggle competitions, as this gives you the chance to improve your score where even so much as a 1% increase can result in placing in the top rankings in a competition. In most stacking solutions, they are tailored specifically for the problem, and this implementation allows you to customise and tailor features for each model.
Approach
I decided to develop a class that would embody all the methods that I would need. This would have the same core methods you would expect a scikit-learn model to have, ie. 'fit', 'predict' etc.
Below I will go through all the elements to the class alongside where you're able to go and find the package. I also wrote a few test runs to ensure that it was working, as well as demonstrate how to use this implementation in any workflow that you have.
Imports
Here we have only 3 imports to complete the stacking class.
We have imported pandas mainly for data handling. There are a number of functions within pandas that make handling data extremely easy and will prove to be useful in future improvements.
We have also imported numpy for some numeric calculations that take place, as well as some useful functions.
We have imported KFold from scikit-learn's "model_selection" module which will help with the blending process as we generate our meta-features for each model.
We have imported pandas mainly for data handling. There are a number of functions within pandas that make handling data extremely easy and will prove to be useful in future improvements.
We have also imported numpy for some numeric calculations that take place, as well as some useful functions.
We have imported KFold from scikit-learn's "model_selection" module which will help with the blending process as we generate our meta-features for each model.
Initialization
Here we can see that we will be storing a lot of variables, mostly from the fit function so that we can store models and more vital variables so that they can be used in the prediction method later on in the class. Each stage is stored as to be able to give a comprehensive look into each of the components, following a fit. This can be useful when trying to see each of the different steps and models used and feature importances for each model.
Storing all these features gives a great opportunity to further develop the class to include an internal score function, model feature importances and other vital pieces of information acquired throughout the fitting phase.
Storing all these features gives a great opportunity to further develop the class to include an internal score function, model feature importances and other vital pieces of information acquired throughout the fitting phase.
Model Validations
When developing an API, in order to ensure that the correct parameters are being entered, assertions are great for ensuring this is the case. I added a model validation step to ensure that the models could in fact be used within the stacking phase. Here I have asserted that the models do in fact have a "predict_proba" or "predict" function. I then append a list which is used to determine which function to use for each model dependant on their index, as well as pass a note to the user if their is no "predict_proba" (a preferred prediction) and there is a "predict" function, that the latter will be used. I look to add mode validations to the class to ensure that the class is as robust as possible, after users have used the class, I will be able to make more informed adjustments to the assertions and directions of use.
Static Predictor method
Here we have a static method that runs the prediction of any of the given model. I have this method as there are a number of predictions taking place and of different variants requiring a conditional filter, and due to this, reducing this to a function allows for a much smaller class.
Fitting the Stacker
The fit method within the stacker is understandably the biggest method of them all seeing as this is where the stacking and fitting of all the models take place. During this method, we can see that we save a lot of the variables that were initialised at the beginning.
Here we start by re-initialising the class. This will remove any variables or models from any previous fits of the model as to ensure a fresh fit is modelled. I then ensure that the X and y variables passed into the fit function are pandas dataframes, as these are easier to handle and have useful functions as mentioned earlier. If they aren't in the desired format, then these are converted to pandas dataframes.
Next, the method looks at the model feature indices. This variable indicates, for each model, which features should be selected from X, given the indices passed. These are easily filtered with an ".iloc[]" method within pandas. If this parameter is not given, then the model will assume that all features should be selected and does so.
Next, the model begins the meta-feature generation phase and enters a loop across all the models, selected features and the prediction method in order to generate the predictions and appends a dataframe where all the meta-features are stored. Within this loop is a conditional argument to take into account whether blending is to take place or not as the blending process is different as this loops through a KFold of the training data to generate predictions.
Once all the meta-features are generated, they are appended to the main training data and the models that were trained to generate the features are stored. The stacker model is then fit with the new training and meta-feature data and stored within the object for predictions later.
Next, the method looks at the model feature indices. This variable indicates, for each model, which features should be selected from X, given the indices passed. These are easily filtered with an ".iloc[]" method within pandas. If this parameter is not given, then the model will assume that all features should be selected and does so.
Next, the model begins the meta-feature generation phase and enters a loop across all the models, selected features and the prediction method in order to generate the predictions and appends a dataframe where all the meta-features are stored. Within this loop is a conditional argument to take into account whether blending is to take place or not as the blending process is different as this loops through a KFold of the training data to generate predictions.
Once all the meta-features are generated, they are appended to the main training data and the models that were trained to generate the features are stored. The stacker model is then fit with the new training and meta-feature data and stored within the object for predictions later.
Predictions
Here we have the prediction method. This is partitioned into 2 parts, one where blending has been applied and one where blending isn't. This method takes the trained models that were built during the "fit" method and builds the metafeatures. If blending has been applied, we will have as many models as there are folds in the data. The default value for the folds is 5, therefore 5 models will then be used to generate the metafeature. Their results will then be averaged out to provide the metafeature for that model type. This will be repeated for each of the models that are to be stacked.
Once all the metafeatures have been generated, the pre-trained stacker will then take the new X data and the metafeatures generated and produce predictions which are then returned.
Once all the metafeatures have been generated, the pre-trained stacker will then take the new X data and the metafeatures generated and produce predictions which are then returned.
Test Script and Examples
Here we have a test script to assess the results of the model. The data used to test the stacker is from sklearn's datasets module. The data is the 'Breast cancer wisconsin (diagnostic) dataset'. This data is a classification datasets in that the targets are binary, either breast cancer is malignant (1) or if it is benign(0). There are 212 malignant cases and 357 benign cases. This dataset consists of 569 cases and 30 numerical features to describe each case. features include things like:
The model used to evaluate the performance are:
The data can be found here (https://goo.gl/U2Uwz2).
- 'mean radius'
- 'mean texture'
- 'mean perimeter'
- 'mean concave points'
- 'mean symmetry'
- 'mean fractal dimension'
The model used to evaluate the performance are:
- Random Forest
- Logistic Regression
- Decision Tree
- Ridge Regression
- Stacker Model
The data can be found here (https://goo.gl/U2Uwz2).
Results
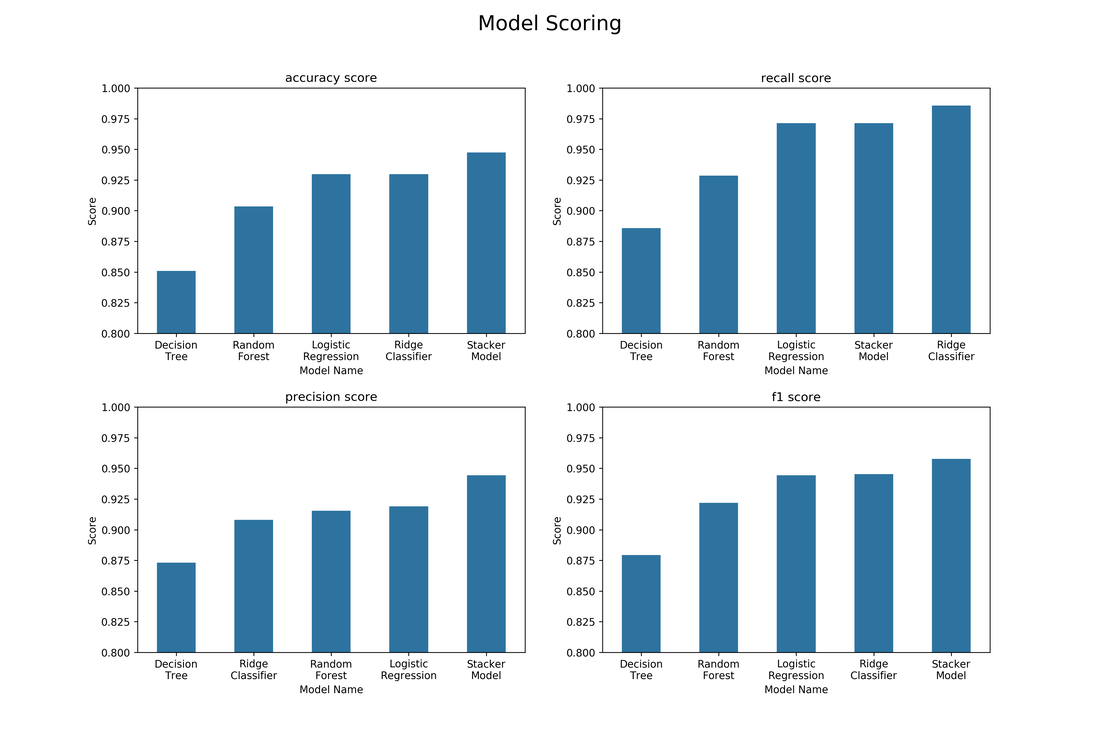
Having run the script above we can have a look at the results. He we can see that the stacker model performs better than all the other models when evaluating the accuracy, precision and f1 score of the model. The ridge classifier, however, performs the best in terms of recall but has a very poor precision score. Based on these scores, we can see that the stacker performs better in general. The model is able to take advantage of the other models by ensembling their scores. The f1 score is an evaluation metric that gives a good all round performance of a model and here we can see that the stacker model performs the best. The blending as well as the ensembling provides the strength in this approach as blending helps generalise the model and ensembling helps improve the predictive power of the model.
Final Thoughts, Ideas and Next Steps...
Overall, we can see that stacking does in fact provide better results but this is then accompanied by increased complexity. As mentioned earlier, model stacking is great for competitions where every small percent is valuable in differentiating yourself from the competition. Hopefully this will provide an easy approach to stacking so that many people can start using it with models from scikit-learn. It can be noted that this is in-fact built with scikit-learn models in mind, however, this could be used with other models granted that they have the same methods that are required. With that in mind, you could stack a bunch of stackers together as this implementation has the relevant methods to do so.
Moving forward, I would like to add more descriptive and diagnostic methods that provide more information about the models used inside the stacker model. Methods that I would like to include are scoring methods, feature importance methods and coefficient methods etc. I would also like to add more assertions and testing in order to ensure the stacker model is as robust as possible.
Moving forward, I would like to add more descriptive and diagnostic methods that provide more information about the models used inside the stacker model. Methods that I would like to include are scoring methods, feature importance methods and coefficient methods etc. I would also like to add more assertions and testing in order to ensure the stacker model is as robust as possible.
To install the package onto your local machine you can find it within pip.

